python爬虫实例代码分析
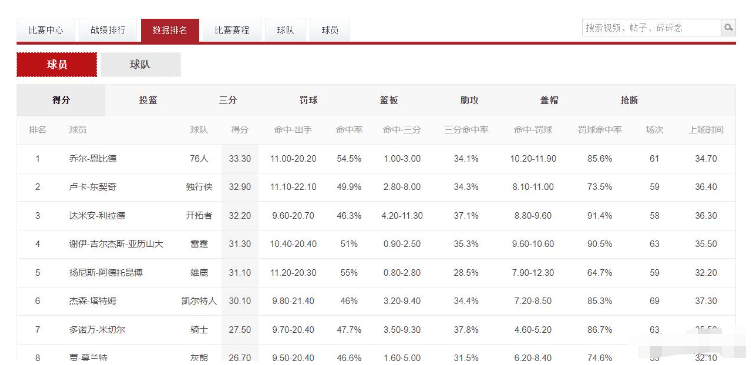
虎扑体育-NBA球员得分数据排行 第1页
示例代码:
import requests
from lxml import etree
url = 'https://nba.hupu.com/stats/players'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
res = requests.get(url=url, headers=headers)
print(res)
# 处理请求结果
e = etree.HTML(res.text)
# 解析响应的数据
player = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[2]/a/text()')
team = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[3]/a/text()')
hit_rate = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[6]/text()')[1:]
score = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[4]/text()')[1:]
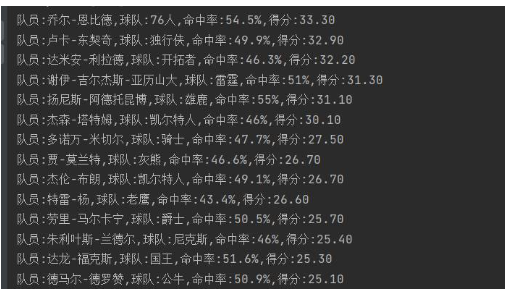
for p, t, h, s in zip(player, team, hit_rate, score):
print(f"队员:{p},球队:{t},命中率:{h},得分:{s}")运行结果: